Area Forecast Discussion Viewer
Published on .
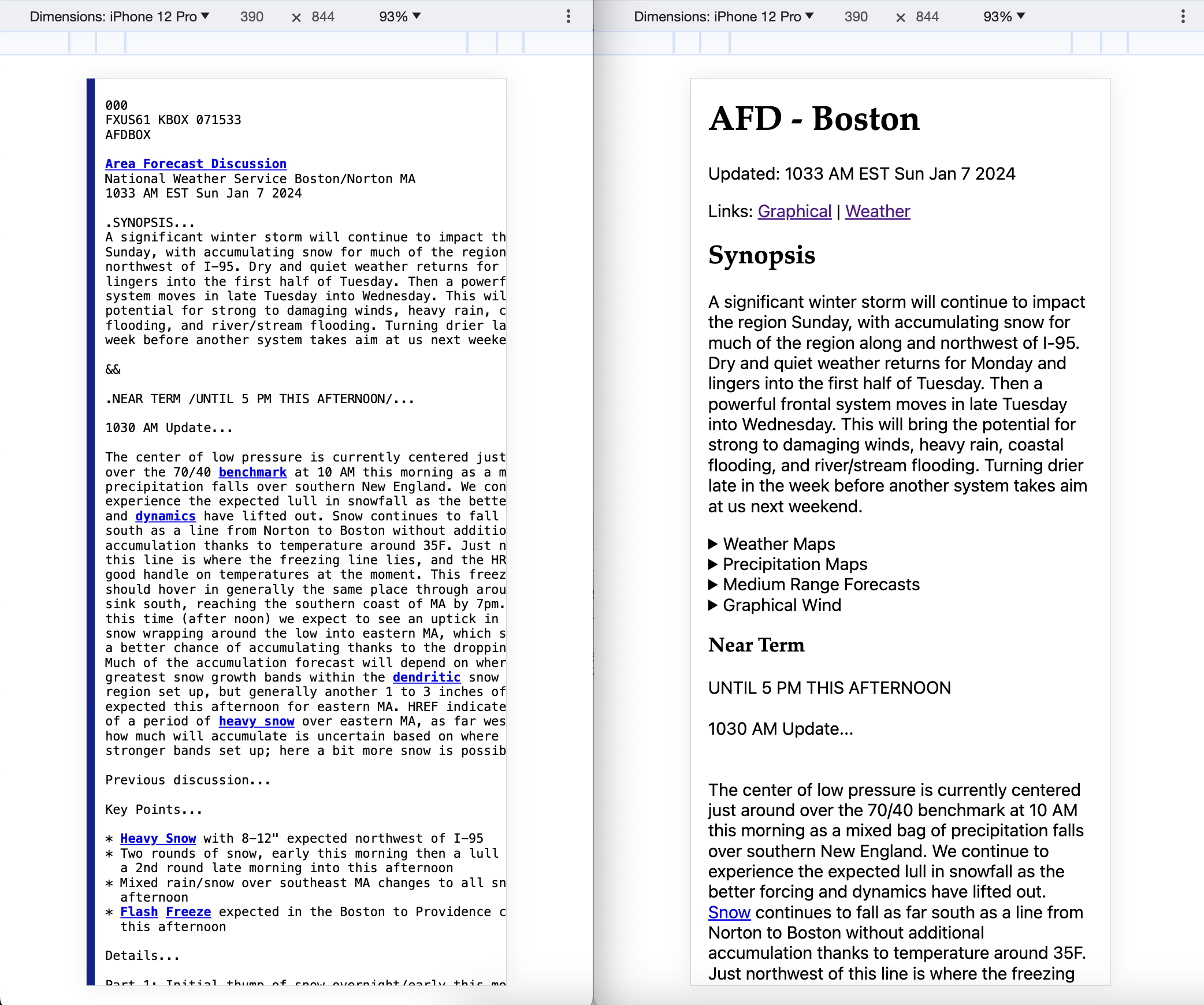
I over-engineered a solution for viewing the NWS’s Area Forecast Discussion (AFD) from my phone. The Area Forecast Discussion published by the National Weather Service is an awesome resource for weather enthusiasts like me since it contains expert analysis and insights about weather models. But the darn thing is pre-formatted text that doesn’t reflow for smaller screens and doesn’t implement the viewport meta tag, so it is a pain to read on small screens due to all the zooming and scrolling. I wrote a python script to fix that which you can try out at https://test.nattaylor.com/afd
If you are wondering why the NWS can’t solve this… they may be working on it, but they are very diligent to ensure backwards compatibility so change takes a long time. Until 2016, the AFD was published in ALL UPPER CASE.
The simplest possible solution for reflow is perhaps the following: "<p>%s</p>" % "</p></p>".join(raw['productText'].split("\n\n")) This supports reflow well, but it does not take advantage of any of the section hierarchy in the AFD. The loose spec “WFO PUBLIC WEATHER FORECAST PRODUCTS SPECIFICATIONS” says there is a topic divider format of .SECTION...{{discussion}}&&\n that we can parse out to add headings. However there is an alternative divider format, watches/warnings sections and the forecasters deviate from the spec from time-to-time. On top of that, they rely on plain text formatting (e.g.) for * bulleted lists.
To implement, I chose to use python executed via CGI and did the parsing with regex. You can view the output here http://test.nattaylor.com:8000/cgi-bin/afd/afd.py and the source at https://gist.github.com/nattaylor/e4a10ad3999d605b07a582dd3ea02e52 (which may be slightly out of date.)
At times, paragraphs got quite long, so I added a lousy chunk-er:
paragraphs = [""]
for s in afd[k].split(". "):
if len(paragraphs[-1]) < 750:
paragraphs[-1] += s + ". "
else:
paragraphs.append(s + ". ")
afd[k] = "<br><br>".join(paragraphs)Sometimes the jargon is technically dense. The NWS offers a glossary which is why certain words are hyperlinked, but it isn’t always comprehensive enough, so I integrated with ChatGPT. If you highlight some text and tap the 🪄 it will call ChatGPT as follows. This works pretty well.
{
"role": "system",
"content": "You are a meteorologist that explains weather phrases."
},
{
"role": "user",
"content": f"What does this weather phrase mean:\n\n\"{prompt['prompt']}\""
}I have lots to (re)consider with this:
- I chose one big regex, but separate regexes for each topic (e.g.
.SYNPOSIS...) might be better, or alternatively just splitting on&&or looking for all occurrences ofr/\n.(.*?)...\n(.*?)&&\n/might be better - Handling newlines correctly is crucial. 2 newlines in a row should display that way, but 1 newline should be replaced with space (except for a few, difficult to identify, special cases.
- Having the Python, template, CSS and JS all in the same file is a bit ugly but it works.