300M Rows in Postgres
Published on .
u/ShippersAreIdiots recently posted that he needed help reducing query times on a Postgres table with 300M rows. He provided the schema and some queries with times, which is not sufficient to get meaningful help. I used it as an excuse to dig into Postgres and here are my initial results. The tl;dr is that you can make queries pretty fast with a beefy, well configured server.
| Query | postgres@14 | tune settings | add index |
|---|---|---|---|
| Q1 | 65 | 38 | 21 |
| Q2 | 0.0097 | 0.0046 | 0.0067 |
| Q3 | 69 | 40 | 19 |
| Q4 | 64 | 37 | 37 |
| Q5 | 60 | 37 | 9 |
| Q6 | 63 | 39 | 37 |
I wanted to do a bunch of things like:
- See the effect of various Postgres settings like max_workers and shared_buffers
- See the effect of various indexes
- See the effect of partitioning
- Learn to read query plans
The schema is:
CREATE TABLE shipments_six_months (
Product_Description TEXT,
Data_Source VARCHAR(500),
Inbound_Country_ISO_Code VARCHAR(10),
Shipment_Date DATE,
Outbound_Country_ISO_Code VARCHAR(10),
Transportation_Mode VARCHAR(500),
Port_Of_Unlading VARCHAR(500),
HS_Code VARCHAR(50),
Port_Of_Lading VARCHAR(500),
Weight_KG FLOAT,
Quantity_Unit VARCHAR(50),
Quantity FLOAT,
Total_Shipment_Value FLOAT,
Shipment_Value_Per_Quantity_Unit_USD FLOAT,
Port_Of_Lading_Country_ISO_Code VARCHAR(10),
Port_Of_Unlading_Country_ISO_Code VARCHAR(10),
consignee_name VARCHAR(500),
shipper_name VARCHAR(500)
)
After installing and running postgres via brew install postgres, the first step was to insert some data. The code below got around 50,000 it/s which was good enough to insert 140M rows while I put my son to bed. I didn’t really confirm, but I took care to insert day-by-day which I assume matches his workload.

From there, I just ran the queries with a little harness to get some baseline numbers. Luckily, my table with 140M rows on my M1 Mac performed reasonably close to what the user reported (even though we don’t know anything about his data or server resources). Great!
Next, I had read that Postgres has conservative defaults so I set shared_buffers = '4096GB'; up from 128M and reran all the queries. This immediately cut the query times almost in half… and I didn’t even have to do any real work or look at any query plans.
Next, I wanted to add an index. In the sample queries outbound_country_iso_code and inbound_country_iso_code are common predicates and total_shipment_value, shipper_name, consignee_name and product_description are common projections. So I created a covering index CREATE INDEX shipments_six_months_covering_idx and viola query time was halved again for 2 of the queries and more for another. The covering index was 17GB compared to 49GB for the table overall. It is pretty wild to me that Postgres will just do that for you… and maintain (if you want) what are effectively multiple copies of the same table laid out as you please.
ON public.shipments_six_months (outbound_country_iso_code, inbound_country_iso_code) INCLUDE (total_shipment_value, shipper_name, consignee_name, product_description);
demo=# select indexname, pg_size_pretty(pg_relation_size(indexname::regclass)) as size from pg_indexes where tablename = 'shipments_six_months';
indexname | size
-----------------------------------+-------
shipments_six_months_covering_idx | 17 GB
(1 row)
demo=# SELECT pg_size_pretty(pg_table_size('shipments_six_months'));
pg_size_pretty
----------------
33 GB
(1 row)This was good progress and I still haven’t even looked at a query plan! The next obvious (but slow) thing to do is create a GiST or GIN index (e.g. CREATE INDEX product_description_tsvector_idx ON shipments_six_months USING GIST (to_tsvector('english', product_description));) and indexes specifically for the other 2 queries.
I also want to explore materialized views, partitioning and query plans still. I think I could:
- Look into how the data is skewed, as well as presence of nulls, via query plans in order to create more good and useful indexes. Covering indexes sort of feel like cheating, so I want to try some specifically designed to speed up aggregating, etc.
- Explore efficient materialized views that could be created
- Explore the use of partitioning, especially whether that allows for parallel sequential scans.
- Explore putting this data in DuckDB
- (Maybe) explore normalizing a bit with the goal of shaving off some bytes to scan.
- Look into logging, pg_stats and automatic index suggestions
- Spend more time understanding memory usage and workers
Updates
Columnar
I got a chance to go back and try this with Hydra’s columnar format. The results are very impressive!
| Query | postgres@15 | columnar |
| Q1 | 6 | 1 |
| Q3 | 8 | 1 |
| Q4 | 8 | 1 |
| Q5 | 7 | 1 |
| Q6 | 8 | 1 |
I’m on a Mac M1, so I ran it inside of Docker and it was very simple:
create extension columnar;
CREATE TABLE shipments_six_months_c (LIKE shipments_six_months) using columnar;
INSERT INTO shipments_six_months_c select * from shipments_six_months;It should be no surprise that columnar format saved tons of space due to the efficiency of packing values of the same type consecutively.
(select 'heap' as format, pg_size_pretty(pg_table_size('shipments_six_months')) as size) union all (select 'columnar' as format, pg_size_pretty(pg_table_size('shipments_six_months_c')) as size);
format | size
----------+---------
heap | 9275 MB
columnar | 2530 MB
(2 rows)Postgres Workload Analyzer (POWA)
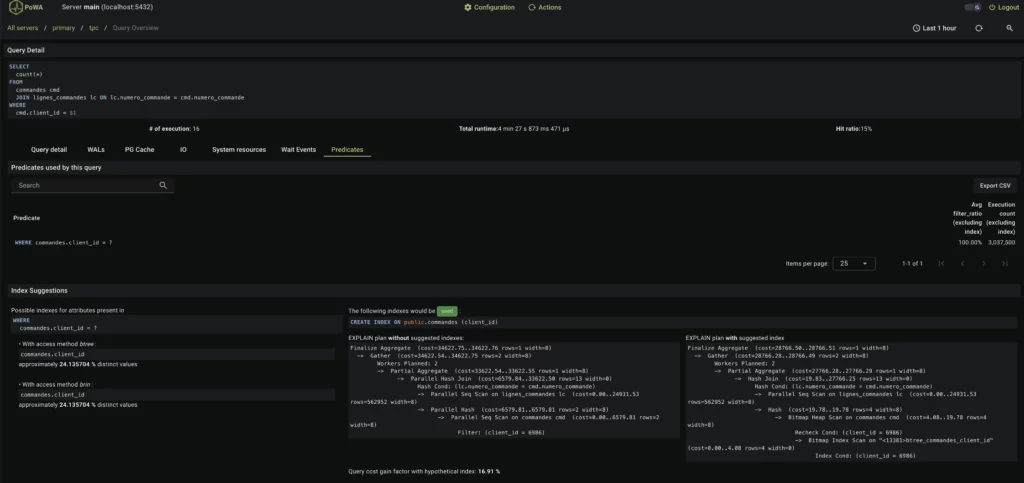
I wanted to also try POWA but I haven’t yet had any luck on Mac M1. Luckily there’s a free instance running for demo! e.g. On this page, using a bunch of extensions to collect stats and hypothetical indexes, it’s able to recommend an index including the hypothetical gain!
Normalization & Column Tetris
There is a big opportunity for normalization. The country codes are varchar(10) which is probably 10-bytes, best case, but there are only 195 countries in the world which would fit into a 1-byte tinyint (up to 255 values). The same would be true for any of the other varchar() columns, if it is possible to known the values in advance. These changes mean smaller tables and indexes, which mean faster queries.
The column order can result in varying levels of column padding, so even more space can be saved if the fixed-size columns (like smallint, float, etc) are ordered largest to smallest.
I did a lazy attempt at this which reduced the table size by about 16% for heap and 20% for columnar.
CREATE TABLE shipments_six_months_packed (
Shipment_Date DATE,
HS_Code int,
Weight_KG FLOAT,
Quantity FLOAT,
Total_Shipment_Value FLOAT,
Shipment_Value_Per_Quantity_Unit_USD FLOAT,
Port_Of_Lading_Country_ISO_Code smallint,
Port_Of_Unlading_Country_ISO_Code smallint,
Outbound_Country_ISO_Code smallint,
Inbound_Country_ISO_Code smallint,
Quantity_Unit smallint,
Data_Source smallint,
consignee_name VARCHAR(500),
shipper_name VARCHAR(500),
Transportation_Mode VARCHAR(500),
Port_Of_Unlading VARCHAR(500),
Port_Of_Lading VARCHAR(500),
Product_Description TEXT
);
--<wait to insert data>
SELECT relname, pg_size_pretty(pg_table_size(oid)) FROM pg_class where relname like 'shipments%';
relname | pg_size_pretty
-------------------------------+----------------
shipments_six_months | 9275 MB
shipments_six_months_c | 2530 MB
shipments_six_months_c_packed | 2030 MB
shipments_six_months_packed | 7769 MB
(4 rows)Code
Query Runner
import psycopg2
import time
def execute_and_time_query(conn, query):
with conn.cursor() as cur:
start_time = time.time()
cur.execute(query)
result = cur.fetchall() # Or fetchone() if you expect a single row
end_time = time.time()
execution_time = end_time - start_time
return result, execution_time
# Database connection parameters (replace with your actual values)
db_params = {
'host': 'localhost',
'database': 'demo',
}
# Example queries
queries = [
"SELECT product_description, sum(total_shipment_value) FROM shipments_six_months_partitioned WHERE outbound_country_iso_code = 'IND' AND inbound_country_iso_code = 'USA' GROUP BY product_description ORDER BY 2 DESC LIMIT 5;",
"SELECT * FROM shipments_six_months_partitioned WHERE weight_kg > 200 AND shipment_date BETWEEN '2024-05-20' AND CURRENT_DATE limit 10;",
"SELECT distinct shipper_name FROM shipments_six_months_partitioned WHERE to_tsvector('english', product_description) @@ to_tsquery('Speaker') AND inbound_country_iso_code = 'USA' AND outbound_country_iso_code IN ('ARG', 'BRA', 'CHL', 'COL', 'ECU', 'GUY', 'PRY', 'PER', 'SUR', 'URY', 'VEN') AND shipper_name <> '' LIMIT 10;",
"SELECT SUM(total_shipment_value) AS total_value FROM shipments_six_months_partitioned WHERE weight_kg > 500 AND quantity >= 10 LIMIT 10;",
"SELECT distinct consignee_name FROM shipments_six_month_partitioneds WHERE to_tsvector('english', product_description) @@ to_tsquery('Speaker & System') AND outbound_country_iso_code = 'USA' AND inbound_country_iso_code IN ('ARG', 'BRA', 'CHL', 'COL', 'ECU', 'GUY', 'PRY', 'PER', 'SUR', 'URY', 'VEN') and consignee_name <> '' LIMIT 10;",
"SELECT shipper_name, SUM(total_shipment_value) as total_value FROM shipments_six_months_partitioned WHERE outbound_country_iso_code = 'USA' GROUP BY shipper_name ORDER BY total_value DESC LIMIT 10;",
]
# Connect to the database
with psycopg2.connect(**db_params) as conn:
for query in queries:
print(f"Query: {query}")
result, execution_time = execute_and_time_query(conn, query)
# print(f"Result: {result}") # Print the result (optional)
print(f"Execution time: {execution_time:.4f} seconds\n")Fake Data Loader
"""Explore Postgres Performance on 300e6 records"""
from faker import Faker
import random
from datetime import date, timedelta
import gzip
import csv
import requests
import multiprocess
from tqdm import tqdm
import psycopg
from mpire import WorkerPool
fake = Faker()
reader = csv.DictReader(requests.get("https://github.com/etano/productner/raw/refs/heads/master/Product%20Dataset.csv").text.splitlines())
products = [row['name'].split(" - ")[0].replace("'", "") for row in reader]
def weighted_country():
"""Attempt to get a semi-realistic skew"""
return random.choices(
['CHN', 'USA', 'DEU', 'GBR', 'FRA', 'NLD', 'JPN', 'ITA', 'SGP', 'IND', 'KOR', 'ARE', 'IRL', 'CAN', 'HKG', 'CHE', 'MEX', 'ESP', 'TWN', 'BEL', 'POL', 'RUS', 'AUS', 'BRA', 'VNM'],
[3511248, 3051824, 2104251, 1074781, 1051679, 949983, 920737, 793588, 778000, 773223, 769534, 753000, 731813, 717677, 673305, 661627, 649312, 615829, 536128, 535173, 469264, 465432, 447506, 389625, 374265],
k=1
)[0]
companies = [fake.company() for _ in range(50000)]
cities = [fake.city() for _ in range(50000)]
def generate_shipment_record(date=None):
"""Generates a fake shipment record."""
Total_Shipment_Value = fake.random_number(digits=6)
Quantity = fake.random_number(digits=4)+1
return (
random.choice(products),
random.choice(companies), #fake.company(),
'USA' if random.random() > 0.33 else fake.country_code(representation="alpha-3"), # Attempt at a semi-realistic skew
date or fake.date_between(start_date="-6m", end_date="today").strftime("%Y-%m-%d"),
weighted_country(), #fake.country_code(representation="alpha-3"),
random.choice(["Sea", "Air", "Road", "Rail"]),
random.choice(cities), #fake.city(),
fake.random_number(digits=10),
random.choice(cities), #fake.city(),
fake.random_number(digits=5),
random.choice(["Pieces", "Kilograms", "Liters"]),
Quantity,
Total_Shipment_Value,
Total_Shipment_Value/Quantity,
fake.country_code(representation="alpha-3"),
weighted_country(), #fake.country_code(representation="alpha-3"),
random.choice(companies), #fake.company(),
random.choice(companies) #fake.company(),
)
days = 90
records = int(1.6e6) # int(50e6/days)
with psycopg.connect("dbname=demo") as conn:
for i in range(days):
tdate = (date.today() - timedelta(days=180-i)).strftime("%Y-%m-%d")
with conn.cursor() as cursor, cursor.copy("COPY shipments_six_months FROM STDIN") as copy, WorkerPool(n_jobs=8) as pool:
for record in pool.imap(generate_shipment_record, [tdate] * records, progress_bar=True, iterable_len=records, progress_bar_options={'desc': tdate}):
copy.write_row(record)
conn.commit()
Appendix
https://wiki.postgresql.org/wiki/Slow_Query_Questions
https://explain.dalibo.com/about
https://github.com/agneum/plan-exporter