Weekend Tinkering on a Wild Kratts Player
Published on .
My 4 year old loves the show Wild Kratts, a subset of which is graciously made available for streaming on PBS Kids. After a bit of weekend tinkering, I’ve made https://nattaylor.com/wk to watch any episode. It was fun, so here’s the story.
The subset on PBS rotates every few weeks and my son wants to watch some of the other 100+ episodes. With a quick search, I discovered the Internet Archive has the full catalog, so I ran some Javascript to get all the URLS and slapped together the barebones page below with a player and links to all the content. I loaded that up on my TV browser and we could any episode! This was functional, but not all that satisfying.
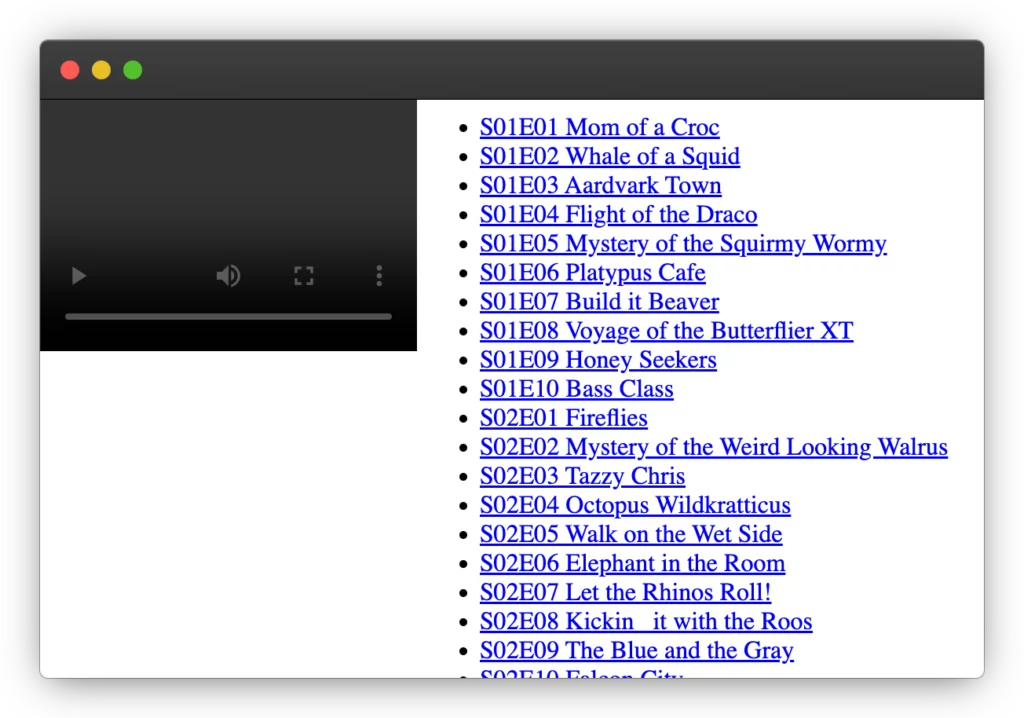
You can view source of https://nattaylor.com/wk.html to see the code, but basically I got the URLs from the following console script and then pasted it into an object.
<code>$$(".directory-listing-table tr").forEach(tr=>if(tr.innerText.includes("ia.mp4")) {console.log(tr.querySelector("a")?.href, tr.querySelector("a")?.innerText)}})</code>Code language: Python (python)Now it was time to start over engineering! My son likes to watch certain animals and sometimes the titles aren’t too obvious, so I ran them through an LLM to extract the animals.
import google.generativeai as genai
from google.ai.generativelanguage_v1beta.types import content
# Create the model
generation_config = {
"temperature": 1,
"top_p": 0.95,
"top_k": 40,
"max_output_tokens": 8192,
"response_schema": content.Schema(
type = content.Type.OBJECT,
properties = {
"animals": content.Schema(
type = content.Type.ARRAY,
items = content.Schema(
type = content.Type.STRING,
),
),
},
),
"response_mime_type": "application/json",
}
model = genai.GenerativeModel(
model_name="gemini-2.0-flash",
generation_config=generation_config,
system_instruction="List all the animals in the Wild Kratts episode",
)
chat_session = model.start_chat( history=[])
for ep in eps:
print(f"{ep['id']} {ep['title']}")
try:
response = chat_session.send_message(f"{ep['id']} {ep['title']}")
except:
time.sleep(15)
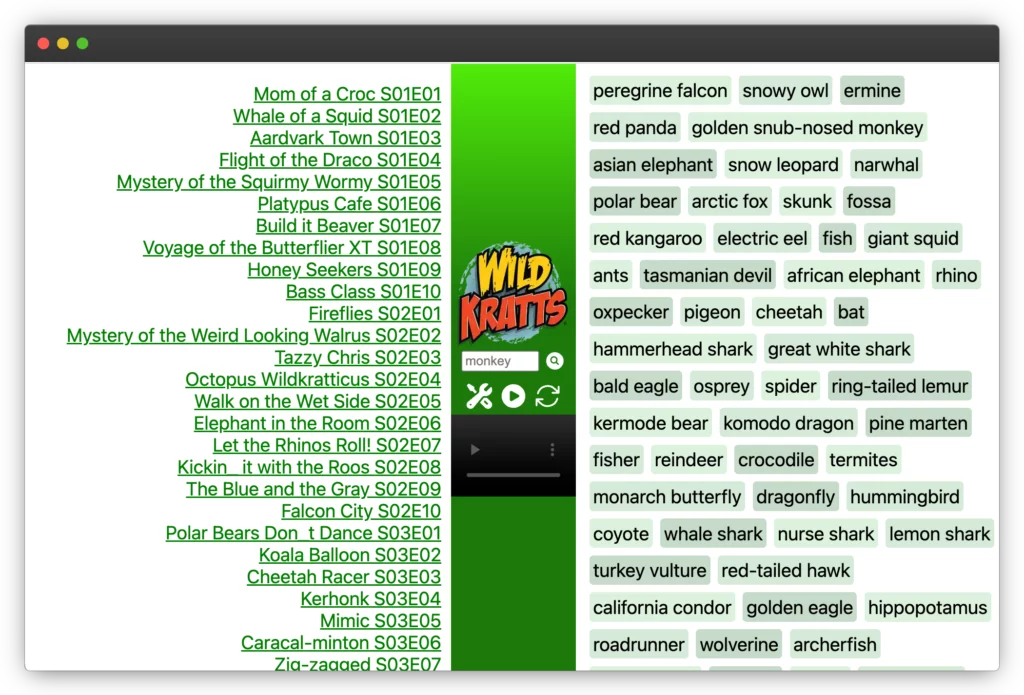
ep['animals'] = [a.lower() for a in json.loads(response.text)['animals']]Code language: Python (python)I updated my JSON object and added a search form. Viola! In doing so, I learned about Array.prototype.some which made it easy to test the search string for membership in the animal list.
let eps = [{'url': 'https://archive.org/download/wild-kratts-season-1-s-01-e-01-mom-of-a-croc/Wild%20Kratts%20Season%201_S01E01_Mom%20of%20a%20Croc.ia.mp4',
'id': 'S01E01',
'title': 'Mom of a Croc',
'animals': ['crocodile', 'fish', 'birds']}]
# q is a search query
eps.filter(ep=>ep.animals.some(animal=>animal.toLowerCase().includes(q)))Code language: Python (python)Next I thought it would be neat to use this to display what the most frequent animals were. I had forgotten about using a lambda within defaultdict!
animals =collections.defaultdict(lambda: {'count': 0, 'episodes': list()})
for ep in eps:
for animal in ep['animals']:
animals[animal]['count'] += 1
animals[animal]['episodes'].append(ep['id'])
# ["peregrine falcon", {"count": 5, "episodes": ["S02E10", "S03E01", "S03E02", "S04E10", "S05E01"]}]Code language: Python (python)When it came to rendering that, I thought it would be neat to vary the colors slightly and it turns out CSS makes that pretty easy now thanks to the new from syntax for relative colors.
#animals a {
background-color: var(--animal-color);
}
#animals a:nth-child(2n) {
background: oklch(from var(--animal-color) calc(l * 0.975) c h);
}
#animals a:nth-child(3n) {
background: oklch(from var(--animal-color) calc(l * 0.925) c h);
}Code language: Python (python)Next up was improving the horrendous UI. This was all designed for the BrowseHere browser app on my TV, which defaults the cursor location to the middle of the screen. So I placed a “Play Random Episode” button and the center, with search right above that. To the left is a “fix” icon which reloads the current video and and “reload” icon which reloads the page. The player is deliberately tiny since BrowseHere automatically detects it and makes it full screen. Perhaps the most interesting learning from all this is that align-content: center; now vertically aligns block content now (in some browsers). The future is now! View source of https://nattaylor.com/wk2.html to see the code if you like.
Now I faced a different challenge. Each episode was encoded in 1080p and weight almost a gigabyte, which was initially OK but turns out the IA is not able to offer that much bandwidth during primetime. So… I figured I’d transcode the episodes. You can pass URLs to ffmpeg so I started there to avoid wasting disk space, but that was only able to achieve about 250kb/s whereas the ia binary could get about 5 MB/s. I didn’t investigate, and instead just let the 100+ GB catalog download overnight. Then I re-encoded and resized. To prepare a file for streaming, its best to move the metadata to the beginning of file and enable good seeking by adding keyframes every 30 seconds. I tried a few other codes like HVEC and AV1, but they didn’t cooperate with BrowseHere, soI used these settings.
ffmpeg -i "$f" -vf "scale=-2:480" -c:v libx264 -crf 40 -preset medium -c:a aac -b:a 128k -movflags faststart -g 30 -keyint_min 30 -tune animation "enc/$(basename $f .mp4).mp4"Code language: Python (python)And that’s a wrap.